


Welcome!
In this notebook and tutorial, we will fine-tune the Mistral 7B model - which outperforms Llama 2 13B on all tested benchmarks - on your own data!
I did this for just one dollar ($1) on an 1x A10G 24GB from Brev.dev (instructions below).
This tutorial will use QLoRA, a fine-tuning method that combines quantization and LoRA. For more information about what those are and how they work, see this post.
In this notebook, we will load the large model in 4bit using bitsandbytes and use LoRA to train using the PEFT library from Hugging Face.
Note that if you ever have trouble importing something from Huggingface, you may need to run huggingface-cli login in a shell. To open a shell in Jupyter Lab, click on 'Launcher' (or the '+' if it's not there) next to the notebook tab at the top of the screen. Under "Other", click "Terminal" and then run the command.
Before we begin: A note on OOM errors
If you get an error like this: OutOfMemoryError: CUDA out of memory, tweak your parameters to make the model less computationally intensive. I will help guide you through that in this guide, and if you have any additional questions you can reach out on the Discord channel or on X.
To re-try after you tweak your parameters, open a Terminal ('Launcher' or '+' in the nav bar above -> Other -> Terminal) and run the command nvidia-smi. Then find the process ID PID under Processes and run the command kill [PID]. You will need to re-start your notebook from the beginning. (There may be a better way to do this... if so please do let me know!)
Before you check out a GPU, prepare your dataset for loading and training.
To prepare your dataset for loading, all you need are two .jsonl files.
If you choose to model your data as input/output pairs, you'll want to use something like the second formatting_func below, which will will combine all your features into one input string.
As you can see below, I have notes.jsonl for my train_dataset and notes_validation.jsonl for my eval_dataset.
I used Exporter, a free local-only app, to export my Apple Notes to .txt files, and then I wrote a script to process each note into one .jsonl file. Note that for this script, ChatGPT can help out a LOT if you tell it how your data is currently formatted, how you'd like it to be formatted, and ask it to write a script in a certain language you know well (for any debugging) to do so. I also broke up my journal entries so the training sample vector length was smaller (see the discussion on max_length and the data visualization below). I broke it into pieces so that contexts were encapsulated entirely, since I did want the model to understand context about my life.
I used a GPU and dev environment from Jarvis.dev. The whole thing cost me $1 using a 1xA10G 24GB. Click the badge below to get your preconfigured instance:
A single A10G (as linked) with 24GB GPU Memory was enough for me. You may need more GPUs and/or Memory if your sequence max_length is larger than 512.
Once you've checked out your machine and landed in your instance page, select the specs you'd like (I used Python 3.10 and CUDA 12.0.1; these should be preconfigured for you if you use the badge above) and click the "Build" button to build your verb container. Give this a few minutes.
A few minutes after your model has started Running, click the 'Notebook' button on the top right of your screen once it illuminates (you may need to refresh the screen). You will be taken to a Jupyter Lab environment, where you can upload this Notebook.
Note: You can connect your cloud credits (AWS or GCP) by clicking "Org: " on the top right, and in the panel that slides over, click "Connect AWS" or "Connect GCP" under "Connect your cloud" and follow the instructions linked to attach your credentials.
Let's now load Mistral - mistralai/Mistral-7B-v0.1 - using 4-bit quantization!
Set up the tokenizer. Add padding on the left as it makes training use less memory.
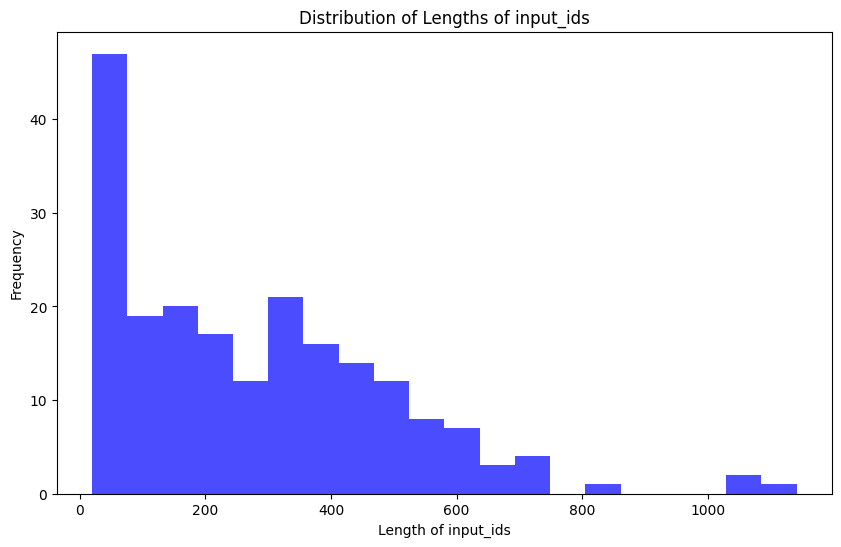
From here, you can choose where you'd like to set the max_length to be. You can truncate and pad training examples to fit them to your chosen size. Be aware that choosing a larger max_length has its compute tradeoffs.
I'm using my personal notes to train the model, and they vary greatly in length. I spent some time cleaning the dataset so the samples were about the same length, cutting up individual notes if needed, but being sure to not cut in the middle of a word or sentence.
Check that input_ids is padded on the left with the eos_token (2) and there is an eos_token 2 added to the end, and the prompt starts with a bos_token (1).
Optionally, you can check how Mistral does on one of your data samples. For example, if you have a dataset of users' biometric data to their health scores, you could test the following eval_prompt:
Now, to start our fine-tuning, we have to apply some preprocessing to the model to prepare it for training. For that use the prepare_model_for_kbit_training method from PEFT.
I didn't have a lot of training samples: only about 200 total train/validation. I used 500 training steps, and I was fine with overfitting in this case. I found that the end product worked well. It took about 20 minutes on the 1x A10G 24GB.
Overfitting is when the validation loss goes up (bad) while the training loss goes down significantly, meaning the model is learning the training set really well, but is unable to generalize to new datapoints. In most cases, this is not desired, but since I am just playing around with a model to generate outputs like my journal entries, I was fine with a moderate amount of overfitting.
With that said, a note on training: you can set the max_steps to be high initially, and examine at what step your model's performance starts to degrade. There is where you'll find a sweet spot for how many steps to perform. For example, say you start with 1000 steps, and find that at around 500 steps the model starts overfitting, as described above. Therefore, 500 steps would be your sweet spot, so you would use the checkpoint-500 model repo in your output dir (mistral-journal-finetune) as your final model in step 6 below.
If you're just doing something for fun like I did and are OK with overfitting, you can try different checkpoint versions with different degrees of overfitting.
It's a good idea to kill the current process so that you don't run out of memory loading the base model again on top of the model we just trained. Go to Kernel > Restart Kernel or kill the process via the Terminal (nvidia smi > kill [PID]).
By default, the PEFT library will only save the QLoRA adapters, so we need to first load the base model from the Huggingface Hub
How funny to see it write like me as an angsty teenager, and honestly adult. I am obsessed. It knows who my friends are and talks about them, and covers the same topics I usually cover. It's really cool.
I hope you enjoyed this tutorial on fine-tuning Mistral on your own data. If you have any questions, feel free to reach out to me on X or Discord.